ARTIFICIAL INTELLIGENCE, DATA & ANALYTICS
BESPOKE DATA VISUALISATIONS
CUSTOM SOFTWARE DEVELOPMENT
CLOUD & OPERATIONS
EMBEDDED SOFTWARE
IOT, CLOUD, DELIVERY & ENABLEMENT
Today, modern application design faces unprecedented challenges driven by the growing demand for data. The phrase “Data is king” has become a mantra in the tech world, and for good reason. Even when an application’s APIs work reliably and are well-supported by developer teams, data remains the central focus of the tech-business landscape.
The data should be delivered quickly, updated on dashboards in near real-time, reflect trends, and provide the ability to react and adapt. – This is now a very common set of business requirements.
Modern businesses aim to build advanced data pipelines that can deliver diverse, actionable insights to their BI teams, boards, and investors—gaining a competitive edge over other companies.
The tech world is adapting to address these needs. In this article, our architect, Artem Avramenko, shares some tricks for dealing with Apache Iceberg and how we benefit from its capabilities at Holisticon.
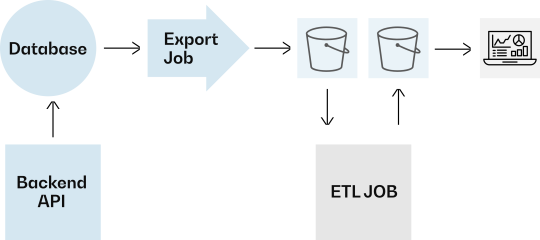
Let’s examine the common data pipeline and architectural designs widely used in today’s applications.
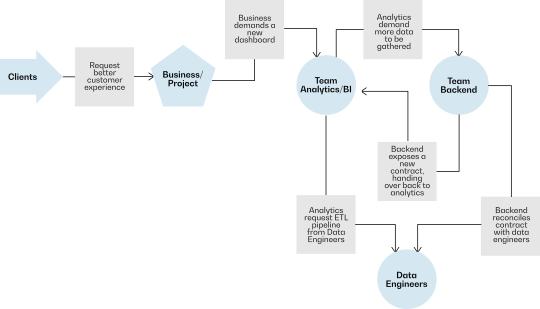
Usually, applications operate independently of data analytics teams, each maintaining its database, data lifecycle, deployments, and infrastructure. Data is typically delivered to analytics and BI teams through well-known ETL (Extract, Transform, Load) pipelines. These ETL processes can take different forms—they may be custom-built to match an organization’s practices or implemented as data streams, nightly jobs, events, or exports. While this is a standard data engineering approach, organizations often face challenges working with such pipelines. Let’s look at a common case:
This process, while functional, introduces numerous challenges. It involves scheduling multiple meetings to establish contracts between teams, coordinating workflows, and managing the significant time and effort required from developers. As a result, such implementations are rarely fast or efficient.
With Apache Iceberg, the architectural perspective can look quite different. But first, let’s discuss the technology itself.
Apache Iceberg is undoubtedly a next-generation solution and a groundbreaking approach. It’s not a technology or framework in the traditional sense, nor is it a programming language. Instead, it’s an open-source, high-performance table format designed for massive analytic datasets.
Let’s look closer at its usage, identify the benefits, and explain why it works.
The diagram shows that a large part of the pipeline is no longer needed. This allows data to be saved directly into the Lakehouse. But how did this become possible, and why wasn’t it a common approach?
The answer lies in the limitations of earlier data warehouses and lakes. One of the biggest challenges was the lack of ACID compliance or the complexity of implementing it. ACID ensures reliable transactional operations on data, including atomicity, consistency, isolation, and durability. Securely updating data in storage systems like S3 was difficult in the past because such systems weren’t designed for these operations. This often resulted in inconsistencies. To address this, ETL pipelines were typically used to manage consistency and re-export data when necessary.
With the Iceberg format, it’s now possible to safely update data directly in the Lakehouse in real time.
And what does this change? A great deal, undoubtedly.
The biggest benefit is that back-end teams can insert or update data directly in the Lakehouse. Additionally, data that isn’t used by the application can be stored only in the Lakehouse. This greatly simplifies the codebase—save the data using Iceberg, and that’s it. No extra lines of code, time wasted, and ongoing support required.
The reliance on ETL pipelines is also significantly reduced. While ETL is still necessary for complex aggregations and AI models, extending existing data pipelines from the back end is no longer required.
This leads to much faster implementation—fewer steps are now required for businesses to get results. It also improves data speed, as the data pipelines are now closer to real-time updates.
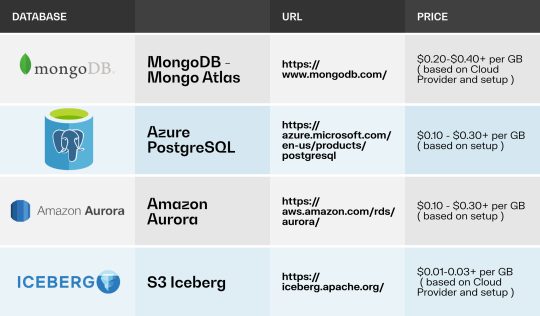
Pricing is another key factor. Back-end databases are notoriously expensive, but now most data can be sent directly to the Data Lakehouse. In one of our projects, we successfully reduced the size of production tables by 15 times by saving data in Iceberg. Storage in the Data Lakehouse is significantly cheaper—often up to 20 times less expensive than database storage. This allows databases to be reserved exclusively for high-priority, real-time data needed by customers, without being overloaded with analytical data.
Adopting a Data Lakehouse architecture is becoming essential for modern application design. By enabling faster access to data, it empowers teams to make quicker decisions, respond more effectively to business needs, and accelerate the delivery of new features. This speed and agility are critical for staying ahead in today’s competitive landscape.
Additionally, as outlined in this article, a Data Lakehouse can significantly streamline development by reducing the size and complexity of the codebase. This simplification lowers maintenance efforts and helps minimize operational and compute costs. Compared to traditional application designs, the Lakehouse approach provides a more efficient and cost-effective solution, making it a key driver for modernizing data infrastructure.
At Holisticon Connect, our core values of Passion and Execution drive us toward a Promising Future. We are a hands-on tech company that places people at the centre of everything we do. Specializing in Custom Software Development, Cloud and Operations, Bespoke Data Visualisations, Engineering & Embedded services, we build trust through our promise to deliver and a no-drama approach. We are committed to delivering reliable and effective solutions, ensuring our clients can count on us to meet their needs with integrity and excellence.